
In recent years, Generative AI has revolutionized how companies can leverage artificial intelligence to generate content, solve complex problems, and improve user experiences.
One of the most advanced techniques in the field of Generative AI is Retrieval-Augmented Generation (RAG), a method that combines the power of text generation with the ability to retrieve information from massive datasets.
In this article, we will explore how RAG works and the crucial role of the sliding window method for chunking in managing textual data.
What is Retrieval-Augmented Generation (RAG)?
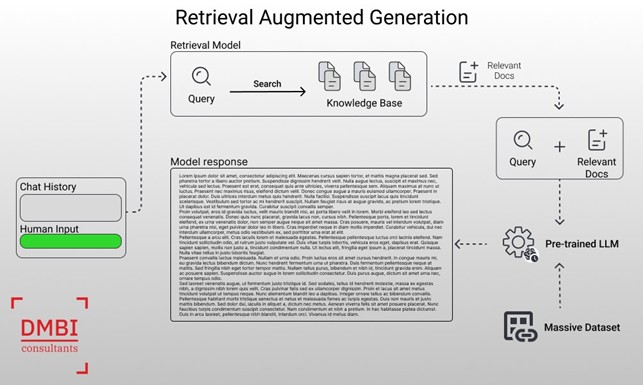
RAG is a technique that enhances the generative capabilities of language models, such as GPT, by integrating the search for relevant information from an external corpus of data. In practice, RAG does not simply generate content based solely on the context provided by the user, but performs a search through a vast database of texts to find the most relevant information to include in the response.
The RAG process can be divided into two main phases:
- Retrieval: The model searches and retrieves relevant text segments from a predefined database or documents. These segments are selected based on their relevance to the user’s query through a scoring system.
- Generation: After gathering the necessary information, the model uses this information to generate a coherent and informative response, enriching the generated text with the previously retrieved data.
The Role of Chunking in RAG
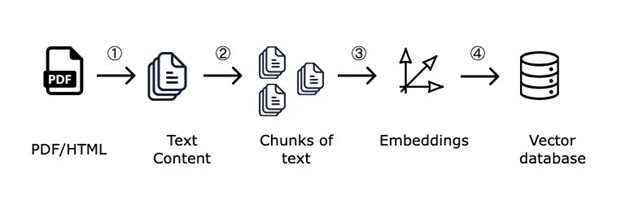
For RAG to work effectively, it is essential that the data within the database is well structured. This is where chunking comes into play, which is the process of dividing long documents into smaller segments called chunks. Each chunk should be short enough to be processed quickly, but at the same time rich in informative content.
The most common method for performing chunking is the sliding window.
Sliding Window Method for Chunking
The sliding window is a simple but very effective technique for segmenting long texts into manageable chunks. This method involves creating moving windows (sliding windows) that overlap along the text, with each window capturing a portion of text.
The following is the operation represented in 3 different key steps:
- Defining the window: Initially, a window of a fixed size is defined. This window slides along the text, creating overlapping segments.
- Sliding the window: The window is slid through the document, moving a certain number of words (e.g., 100 words) each time. This process creates chunks that partially overlap, ensuring that important context is not lost between one chunk and the next.
- Overlap: The overlap between successive windows ensures that no relevant information is lost. This is particularly important for maintaining coherence and context during information retrieval.
Adopting a sliding window-based approach has the following advantages:
- Preservation of context: Ensures that the segments contain enough context to be meaningful on their own, reducing the risk of information fragmentation.
- Flexibility: This method is adaptable to different types of texts and segment sizes, making it versatile.
- Computational optimization: Allows large amounts of data to be managed more efficiently, without compromising the quality of the retrieved information
In conclusion, RAG represents a significant step forward in Generative AI, integrating information retrieval capabilities with content generation to produce extraordinarily accurate and relevant results.
The sliding window method for chunking plays a fundamental role in this process, ensuring that information is managed efficiently and that generative models can produce high-quality results.
Authors: Andrea Fiore and Alfonso Russo | DMBI Data Scientists
Photo by Gemini




