
Negli ultimi anni la Generative AI ha rivoluzionato il modo in cui le aziende possono sfruttare l’intelligenza artificiale per generare contenuti, risolvere problemi complessi e migliorare le esperienze utente.
Una delle tecniche più avanzate nel campo della Generative AI è il Retrieval-Augmented Generation (RAG), un metodo che combina la potenza della generazione di testo con la capacità di recuperare informazioni da enormi set di dati.
In questo articolo, esploreremo il funzionamento del RAG e il ruolo cruciale del metodo dello sliding window per il chunking nella gestione dei dati testuali.
Cos’è il Retrieval-Augmented Generation (RAG)?
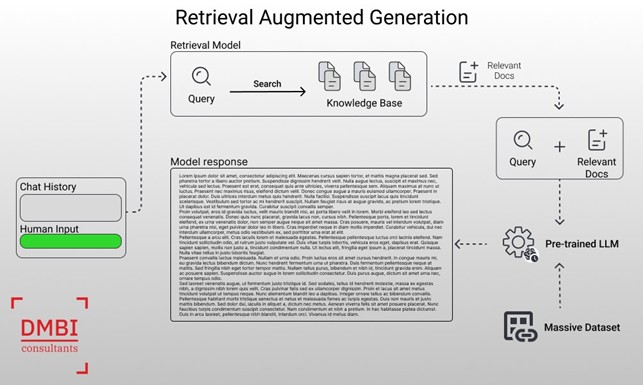
Il RAG è una tecnica che migliora le capacità generative dei modelli di linguaggio, come GPT, integrando la ricerca di informazioni rilevanti da un corpus di dati esterno. In pratica, il RAG non si limita a generare contenuti basandosi solo sul contesto fornito dall’utente, ma esegue una ricerca tra un vasto database di testi per trovare le informazioni più pertinenti da includere nella risposta.
Il processo del RAG può essere diviso in due fasi principali:
- Recupero (Retrieval): il modello cerca e recupera segmenti di testo rilevanti da un database predefinito o da documenti. Questi segmenti vengono selezionati in base alla loro rilevanza rispetto alla query dell’utente tramite un sistema di scoring.
- Generazione (Generation): dopo aver raccolto le informazioni necessarie, il modello utilizza queste informazioni per generare una risposta coerente e informativa, arricchendo il testo generato con i dati recuperati in precedenza.
Il ruolo del chunking nel RAG
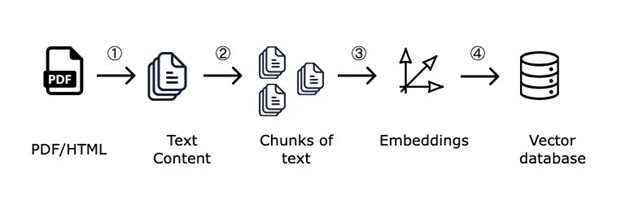
Affinché il RAG funzioni efficacemente, è fondamentale che i dati all’interno del database siano ben strutturati. È qui che entra in gioco il chunking, ossia il processo di suddivisione di lunghi documenti in segmenti più piccoli detti chunks. Ogni chunk deve essere sufficientemente breve da essere elaborato rapidamente, ma allo stesso tempo ricco di contenuto informativo.
Il metodo più comune per eseguire il chunking è quello dello sliding window.
Metodo dello sliding window per il chunking
Lo sliding window è una tecnica semplice, ma molto efficace per segmentare testi lunghi in chunks di dimensioni gestibili. Questo metodo prevede la creazione di finestre mobili (sliding windows) che si sovrappongono lungo il testo, con ogni finestra che cattura una porzione di testo.
Di seguito il funzionamento rappresentato in 3 diversi step chiave:
- Definizione della finestra: inizialmente, viene definita una finestra di dimensione fissa. Questa finestra scorre lungo il testo, creando segmenti sovrapposti.
- Scorrimento della finestra: la finestra viene fatta scorrere attraverso il documento, spostandosi di un certo numero di parole (ad esempio 100 parole) ogni volta. Questo processo crea dei chunks che si sovrappongono parzialmente, assicurando che il contesto importante non venga perso tra un chunk e l’altro.
- Sovrapposizione: la sovrapposizione tra le finestre successive garantisce che nessuna informazione rilevante venga persa. Questo è particolarmente importante per mantenere la coerenza e il contesto durante il recupero delle informazioni.
Adottare un approccio basato su sliding window comporta i seguenti vantaggi:
- Conservazione del contesto: garantisce che i segmenti contengano abbastanza contesto per essere significativi da soli, riducendo il rischio di frammentazione delle informazioni.
- Flessibilità: questo metodo è adattabile a diversi tipi di testi e dimensioni di segmenti, rendendolo versatile.
- Ottimizzazione Computazionale: permette di gestire grandi quantità di dati in modo più efficiente, senza compromettere la qualità delle informazioni recuperate.
In conclusione, il RAG rappresenta un passo avanti significativo nella Generative AI, integrando capacità di recupero di informazioni con la generazione di contenuti per produrre risultati straordinariamente accurati e rilevanti.
Il metodo dello sliding window per il chunking svolge un ruolo fondamentale in questo processo, assicurando che le informazioni siano gestite in modo efficiente e che i modelli generativi possano produrre risultati di alta qualità.
Autori: Andrea Fiore e Alfonso Russo | DMBI Data Scientists
Foto di Gemini




